Was macht eigentlich EMIL? – Adaptives Lernen im Lernmanagementsystem ILIAS
![]() Im Verbundprojekt ELe-com entwickelt und erprobt das CODIP in Kooperation mit verschiedenen Partner:innen eine digitale adaptive Lernanwendung für die berufsbezogene Weiterbildung zum Thema Customer Journey/E-Commerce für das ILIAS-basierte Lernmanagementsystem myFlexNet.de. In den letzten Monaten haben wir neben der Produktion von Mikro-Lerneinheiten im Text-, Audio- und Video-Format zum Thema Customer Journey auch intensiv an dem KI-unterstützten Entscheidungsmodul EMIL gearbeitet.
Im Verbundprojekt ELe-com entwickelt und erprobt das CODIP in Kooperation mit verschiedenen Partner:innen eine digitale adaptive Lernanwendung für die berufsbezogene Weiterbildung zum Thema Customer Journey/E-Commerce für das ILIAS-basierte Lernmanagementsystem myFlexNet.de. In den letzten Monaten haben wir neben der Produktion von Mikro-Lerneinheiten im Text-, Audio- und Video-Format zum Thema Customer Journey auch intensiv an dem KI-unterstützten Entscheidungsmodul EMIL gearbeitet.
Ziel des zu entwickelnden KI-Modul EMIL ist es, Empfehlungen zu individuellen Lernpfaden und Lernangeboten auf Grundlage der Bedürfnisse der jeweiligen Nutzer:innen zu geben. Zu diesem Zweck wurden verschiedene Empfehlungssysteme systematisch untersucht, um ihre Eignung für das Projekt zu ermitteln. Das Hauptaugenmerk lag dabei auf den zu erwartenden Daten, die entweder direkt aus dem Lernmanagementsystem (LMS) ILIAS oder indirekt über eingebettete Plug-ins wie H5P bezogen werden. Die so erhaltenen Daten werden in einem Learning Record Store (LRS) gespeichert. Die damit erstellten Nutzerprofile liefern der KI weitere Test- und Trainingsdaten. Nach dem Vergleich von elf Empfehlungssystemen wurde ein hybrides Modell entwickelt, das aus einem kollaborativen und einem inhaltsbasierten Empfehlungssystem (Recommender System) besteht.
Begleitend wird von unserem Partner Qualitus GmbH das Modul LENA innerhalb von ILIAS entwickelt, um die unterschiedlichen Motivationen, Erwartungen und Voraussetzungen der Zielgruppe sowie deren Lernpräferenzen beim digitalen Lernen zu erheben.
Zusätzlich zu den Nutzer:innendaten, die über LENA erhoben werden, dienen EMIL sämtliche Interaktionsdaten der Lernenden mit den Mikrolerneinheiten (MLE) als Input. Um die MLE zu klassifizieren und die Ähnlichkeiten zueinander zu identifizieren, wird eine Support Vector Machine mit Kosinus-Ähnlichkeit eingesetzt. Als Output liefert EMIL eine Vorhersage der Interaktionswahrscheinlichkeiten der Nutzer:innen mit anderen MLE im LMS.
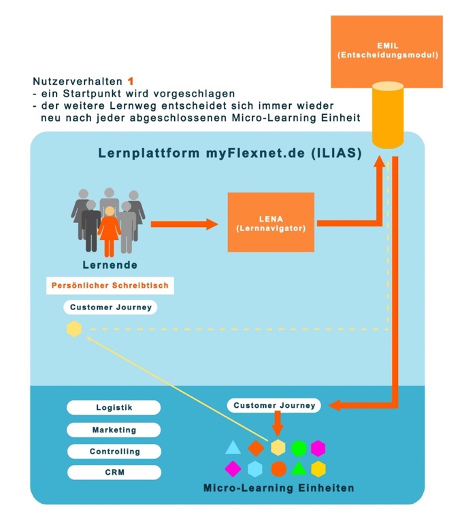
Schließt ein:e Nutzer:in eine MLE ab, erstellt das Empfehlungssystem für jede:n Nutzer:in einen neuen personalisierten Lernpfad. Die Feststellung, wann eine MLE beendet ist, kann je nach Medientyp unterschiedlich ausfallen. Erhält EMIL solch ein sogenanntes Event, verarbeitet es alle ihm vorliegenden Daten. Auf Grundlage dieser Auswertung trifft EMIL Entscheidungen für passende Lerninhalte, welche an LENA zurückgegeben und den Lernenden als Empfehlung präsentiert werden (siehe Abbildung 1).
Bekannte Herausforderungen beim Einsatz von KI stellen das Problem der Datenknappheit und das Cold-Start Problem dar. Im Rahmen des Projekts wird die Lösung beider unter Einsatz verschiedener Strategien untersucht und eine Bewältigung wie folgt angestrebt:
- Das Problem der Datenknappheit ergibt sich aus einer zu geringen Anzahl von Trainingsdaten.[1] Um dies zu umgehen, werden im Projekt zwei Strategien erprobt:
- Online-Batch Training: Das neuronale Netz wird während des Betriebs trainiert und evaluiert.
- Generative Adversarial Network (GAN): Das neuronale Netz wird vor der Ausführung des Modells mit künstlich generierten Daten ergänzt und trainiert, um so die Genauigkeit der Gewichte einzelner Neuronen zu verbessern. Die künstlichen Daten basieren dabei auf wenigen, aber realen Daten von Nutzer:innen.
- Das Cold-Start Problem ergibt sich daraus, dass das System keine Aussagen über Nutzer:innen treffen kann, über die es noch nicht genügend Informationen gesammelt hat. Um diese Tatsache zu umgehen, wird eine Initiativumfrage durchgeführt, die dem KI-Modell erste Informationen über die/den Nutzenden liefert, bevor das System die Vorhersagen trifft.
Sobald wir im Projekt ausreichend MLE zum Thema konzipiert und produziert haben, wird EMIL getestet und angepasst. Für uns bleibt es also spannend!
Autor*innen: Maria Müller, Robert Lorenz
[1] Die geringe Anzahl an Trainingsdaten ergibt sich aus dem Umstand, dass einerseits zu wenige (Test-) Nutzende verfügbar sind und dass andererseits LENA als Teilprodukt noch nicht fertig ist. Deshalb können bisher keine Testnutzer:innen über LENA Daten an uns übermitteln.



